Hermes on RTX: The “Always-On” AI Agent Era Just Got Real
Hermes is a self-improving, always-on AI agent now running locally on NVIDIA RTX PCs and DGX Spark—open-source, provider-agnostic, and built to remember and get better with every task.

Imagine this: you’ve got an AI that works like a quiet employee in the background—drafting, summarizing, scheduling, and improving its own workflow—without shipping your data off to someone else’s cloud. Sounds like sci-fi, right? Here’s the thing… it’s basically what Hermes is aiming to do, and NVIDIA is openly betting on it.
Nous Research’s Hermes Agent is now running on NVIDIA RTX PCs and DGX Spark hardware, and NVIDIA featured it in their RTX AI Garage ecosystem as an example of what “agentic AI” is supposed to look like when it grows up: always on, local-first, and self-improving. [2][3]
The problem: cloud AI is useful… and kind of a leaky bucket
Look, I’ll be honest… I love cloud AI for speed and convenience. But for a lot of entrepreneurs and creators, it comes with three recurring headaches:
- Costs creep up (usage-based pricing is a suspense thriller you didn’t ask for).
- Context resets (your “assistant” forgets how you work unless you keep re-explaining).
- Privacy gets fuzzy (client docs, campaign data, internal SOPs—do you really want all that leaving your machine?)
So the real need isn’t “a smarter chatbot.” It’s a reliable agent that can run in the background, remember what matters, and get better at your workflows over time.
The solution: Hermes + RTX PCs + DGX Spark = a local, self-improving agent
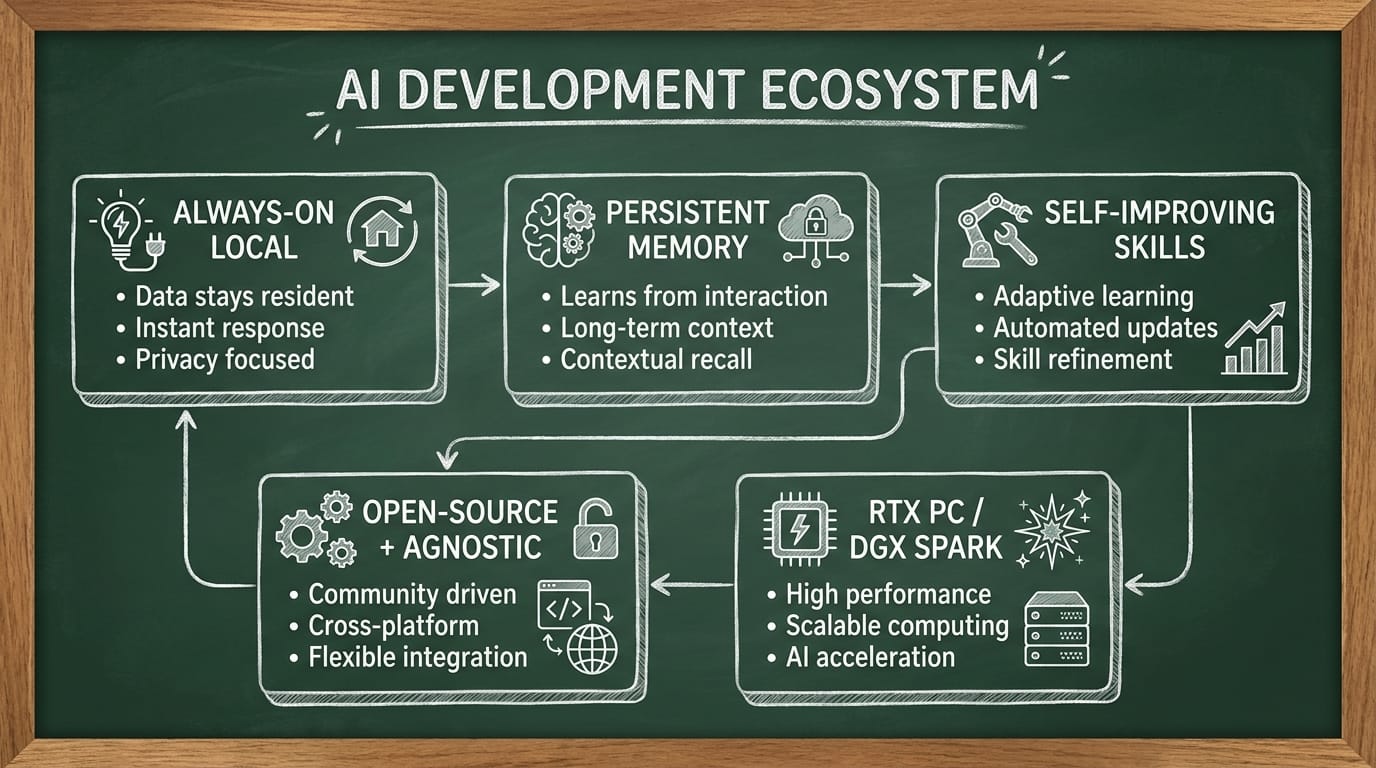
NVIDIA’s framing is pretty clear: Hermes is part of a shift from “ask a question, get an answer” to “give it a goal, let it plan and execute.” In NVIDIA’s own write-up, Hermes is positioned as a self-improving AI agent designed to run on NVIDIA RTX PCs/workstations and especially well on DGX Spark—an always-on box built for hosting local models with lots of memory. [2][3]
In plain English, here’s what makes Hermes different (and why you should care):
- It’s built for always-on local useIt can run background and scheduled jobs on your own hardware, instead of living entirely in a browser tab. NVIDIA specifically calls out always-on usage on RTX systems. [2][3]
- It has persistent memoryNot “remember this one thread” memory. More like: it keeps a local record of tasks, outcomes, and context so the agent becomes more personalized over time. [3]
- It turns repeats into “skills” (and improves them)Think of a skill like a reusable SOP: “Draft newsletter,” “Summarize comments,” “Create campaign recap.” Hermes can refine these as it runs them, so June-you isn’t stuck re-training May-you’s assistant. [3]
- It’s open-source and provider-agnosticThis is huge. Hermes isn’t a locked SaaS. NVIDIA links directly to the open-source project, and the design supports different models/backends (including local runtimes like Ollama / LM Studio). [2][3]
- It runs on RTX PCs and scales nicely to DGX SparkOn an RTX PC, you can run Hermes locally; on DGX Spark, you’re basically hosting an agent server you can access remotely (even from your phone). NVIDIA highlights DGX Spark as a natural home for agents like this. [3]
Here’s what most people miss… “local” isn’t the headline—self-improving is
Running locally is great for privacy and cost control. But the interesting part is Hermes being designed to accumulate competence. That’s the difference between:
- a chatbot that helps when you poke it, and
- an agent that slowly becomes your business’s operating system for repeatable work.
It’s like the difference between a calculator and a spreadsheet template you’ve been refining for years. Same basic tool category… totally different leverage.
Quick Wins: 3 ways a local Hermes agent pays off fast
- Daily briefing skill: every morning, summarize inbox + key metrics + priorities into a one-page brief. (Hermes supports scheduled tasks, cron-style.) [3]
- Content repurposing skill: turn one blog/video into posts for LinkedIn, X, and a short email—stored in your brand voice and refined as you edit. [3]
- Community pulse skill: summarize comments/DMs daily, flag common objections, draft replies in your tone (and learn which replies you actually use).
Common Mistakes (so you don’t rage-quit on day two)
- Trying to automate everything firstStart with one repeatable workflow. Prove it works. Then expand.
- Not defining “done”Agents thrive on clear outputs: “one-page summary,” “draft + 3 variants,” “top 5 insights.” Vagueness = weird results.
- Picking a model that’s too big for your hardwareNVIDIA highlights running models like Qwen via local runtimes; match model size to your GPU/box so it’s fast enough to be usable. [2][3]
FAQ
Is Hermes actually endorsed by NVIDIA?
NVIDIA featured Hermes in their RTX AI Garage content and published a post specifically about Hermes running on RTX PCs and DGX Spark. [2][3]
Do I have to use one specific AI model?
No—Hermes is designed to be provider- and model-agnostic. NVIDIA mentions pairing it with local runtimes like LM Studio and Ollama (and models such as Qwen) rather than locking you into one vendor. [2][3]
Why does DGX Spark matter here?
DGX Spark is positioned as a compact, always-on machine with lots of memory for hosting larger local models and headless agents you can access remotely. It’s basically a “home base” for a persistent agent. [3]
Does “local” really save money?
Often, yes—especially if you’re doing always-on work (summaries, monitoring, drafting) that would otherwise rack up API usage. NVIDIA explicitly calls out reduced cloud reliance and keeping data local with DGX Spark setups. [3]
The bottom line is… this is a real shift in how AI gets delivered
NVIDIA spotlighting Hermes isn’t just a nice blog feature—it’s a signal. We’re moving from cloud-dependent chatbots toward locally-powered agents that:
- run 24/7 on your hardware (RTX PC or DGX Spark),
- keep persistent memory,
- turn repeated work into skills, and
- get better every time you use them.
And for entrepreneurs and creators? That’s not a toy. That’s infrastructure.
Action Challenge
Pick one repeating task you do every week (newsletter draft, comment summaries, campaign recap). Write a one-sentence “definition of done.” If you’re exploring Hermes, make that your first skill. You’ll learn more in a weekend than you will in two months of AI Twitter threads.
Sources: NVIDIA RTX AI Garage blog post featuring Hermes and RTX PCs [2]; NVIDIA DGX Spark Hermes guide and setup notes (persistent memory, scheduler, messaging gateway) [3].