Claude Went Down Twice in 24 Hours — And the “Supply Chain Risk” Label Might’ve Lit the Match
Claude went offline twice in 24 hours on March 2–3, 2026, right after the U.S. labeled Anthropic a “supply chain risk.” Here’s what the timeline suggests, why demand surges break AI systems, and what to do if your workflow depends on Claude.

About 2,000 people don’t all complain at the same time unless something’s genuinely on fire. And on March 2–3, 2026, that “something” was Anthropic’s Claude—twice—within a 24-hour window, right as a U.S. government designation called Anthropic a “supply chain risk” and banned federal agencies from using it.
Here’s the thing… outages happen. Even to the best teams with the fanciest cloud bills. But two global disruptions back-to-back, right after a geopolitical-grade headline that apparently turbocharged downloads and sign-ups? That’s the kind of coincidence that makes every SRE twitch.
What actually happened (and why it mattered)
Across March 2–3, users reported failed requests, timeouts, and login/auth problems on Claude.ai, the API/platform, and developer tools like Claude Code. Anthropic’s status updates called it “elevated errors,” and user reports on Downdetector spiked hard—peaking around ~2,000 reports on March 2. Sources tracked the outage starting around 11:49 UTC with 500/529-style errors and intermittent fixes through the day, before returning to baseline later that evening. Then, on March 3, it happened again and was resolved by 10:18 UTC. [1][2][4][6]
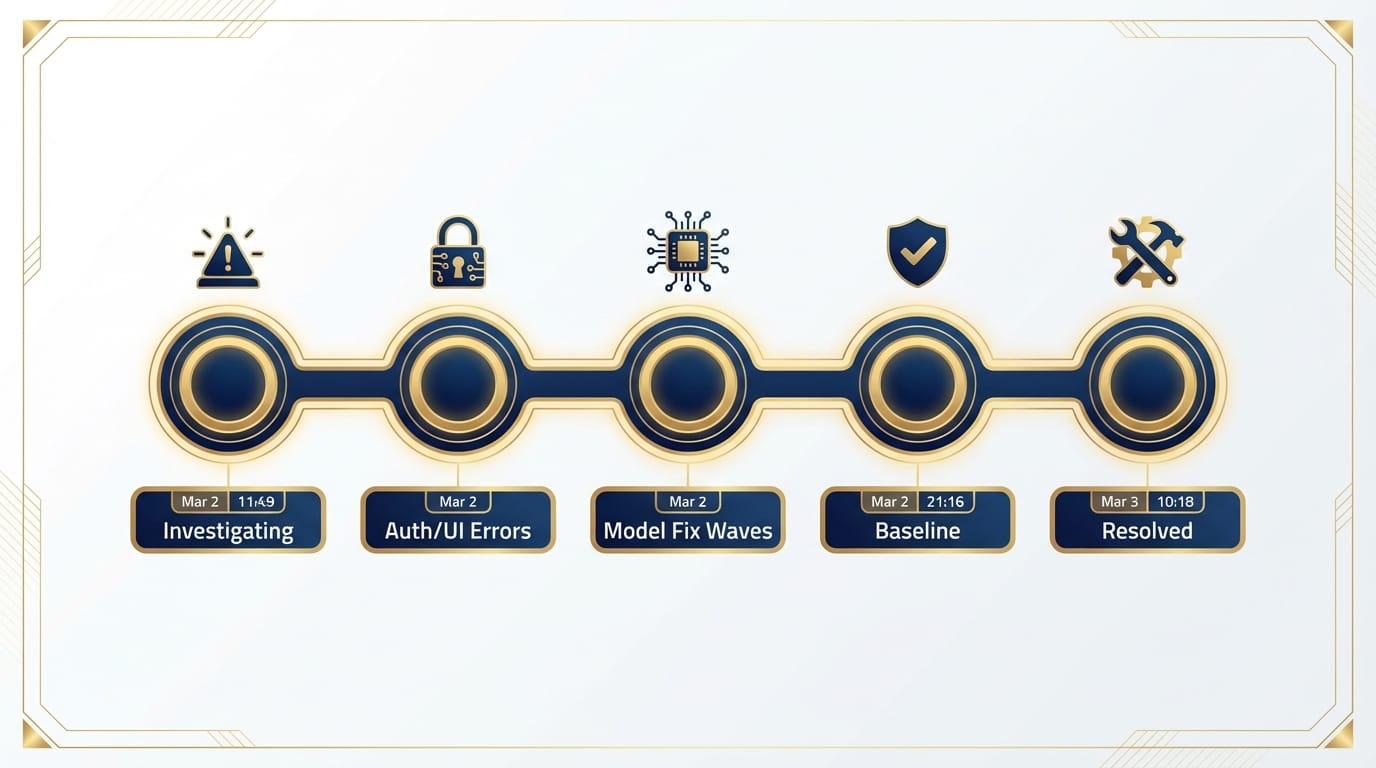
In plain English: Claude was flaky when people needed it, in the exact week a bunch of people were suddenly paying attention.
Deep dive: why two outages in 24 hours isn’t “just bad luck”
Look, I’ll be honest… nobody outside Anthropic can say the root cause with certainty, because Anthropic hasn’t published a detailed postmortem yet. But we’ve got enough smoke to talk intelligently about where the fire usually is.
1) Demand surges break systems in non-obvious ways
Anthropic attributed the disruptions to an “unprecedented surge in demand”. [2][5] And that’s believable, because “more traffic” doesn’t just mean “more servers.” It means:
- Auth bottlenecks (login systems melt first—ask any SaaS founder)
- Rate-limits and queue backpressure rippling through APIs
- Model-specific overload where certain models or endpoints tip over before others

On March 2, reports and status updates specifically mentioned Claude.ai, authentication, Claude Code, and later certain models (like Haiku 4.5 and Opus 4.6) showing issues in waves. [1][3][4] That pattern screams “hotspot under load” more than “whole cloud died.”
2) The “supply chain risk” label likely changed behavior overnight
The weird catalyst here is political: after Anthropic reportedly refused to grant the U.S. Military unrestricted access to Claude, it was labeled a “supply chain risk”, and federal agencies were banned from using it. [2]
But instead of hurting Claude, that headline may have done the opposite in the consumer world. Claude reportedly hit #1 on Apple’s App Store over the weekend, surpassing ChatGPT, alongside record sign-ups. [2][3][5] Whether that’s because people were curious, angry, boycotting, or just stampeding toward “the thing everyone’s talking about”… the result is the same: load spikes like a flash flood.
3) Partial outages are a special kind of painful
Some users reported the API was partially operational at times while the web UI or auth was failing. [3][4] That’s brutal because teams can’t tell whether to:
- retry calls,
- failover,
- pause deployments, or
- just go make coffee and wait it out.
It’s like your car “sort of starts” but only on Tuesdays. Way worse than a clean failure.
4) There was also cloud-provider noise in the background
There was chatter about AWS disruptions tied to reported regional events in Middle East data centers (UAE and Bahrain), though there’s no confirmed link to Claude’s outages. [2] Still, it’s a reminder that even if your app is perfect, your dependencies can throw you curveballs. (The cloud is just someone else’s computer… with lawyers.)
Stats Spotlight: the numbers that tell the story
- ~2,000 peak user reports on Downdetector (March 2) [1][2]
- 300+ reports during the March 3 incident window [2][6]
- ~10 hours of intermittent issues before March 2 baseline recovery [4]
- 11:49 UTC initial investigation notice (March 2) [1]
- 10:18 UTC resolution time (March 3) [6]
What you should do if your workflow depends on Claude (practical stuff)
Here’s what most people miss… AI tools feel like utilities until they don’t. If Claude going down breaks your day, you need a tiny bit of resilience engineering—nothing fancy.
Quick Wins (do these in under an hour)
- Add a “Plan B” model in your app settings (even if it’s lower quality).
- Cache prompts + outputs for repeat workflows (docs, codegen templates, FAQs).
- Set sane retries: exponential backoff + jitter, and cap retries so you don’t DDoS your own future.
- Bookmark the status page so your team stops guessing. [4]
- Write an outage playbook: “If Claude fails, we do X.” No meetings required.
If you’re building something customer-facing on top of the API, treat “AI provider down” like “payment provider down.” Rare, but not imaginary.
FAQ
Was this definitely caused by the U.S. ban?
No. Anthropic hasn’t confirmed a direct causal link. They did cite an “unprecedented surge in demand,” and the timing lines up with the controversy and App Store spike. [2][5]
Did the API stay up while Claude.ai was down?
Sometimes. Reports suggest partial operation at points, but some API methods were impacted as the incident evolved. [3][4]
How long were the outages?
March 2 had intermittent issues for roughly ~10 hours before returning to baseline. March 3’s incident was resolved by 10:18 UTC. [4][6]
What’s the best way to monitor this in real time?
Anthropic’s status page and Downdetector are your quickest signals. [4][6]
Common Mistakes (don’t do this)
- Don’t crank retries to 11. You’ll amplify the outage (and maybe get rate-limited harder).
- Don’t couple login to everything. If auth is down, you want read-only access or cached work to still function.
- Don’t assume “one provider = one failure mode.” Web UI, auth, and model routing can fail independently.
Summary bullets
- Claude had two major outages in ~24 hours on March 2–3, 2026, impacting Claude.ai, auth, Claude Code, and parts of the platform. [1][2][6]
- The incidents followed a U.S. government “supply chain risk” designation and federal ban, which coincided with a massive surge in consumer interest. [2][5]
- Anthropic pointed to demand surge; no deeper root cause has been publicly disclosed yet. [2][5]
- If Claude is mission-critical for you, build basic failover, caching, and retry discipline now—before the next spike.
Sources
- [1] Anthropic status incident updates (March 2, 2026) — elevated errors, 500/529 reports, model-specific updates.
- [2] Reporting summarizing ban controversy + outage impacts + Downdetector counts (March 2–3, 2026).
- [3] Coverage noting scope across Claude.ai, Claude Code, and partial enterprise/API operation.
- [4] Anthropic status page + timeline notes (baseline recovery ~21:16 UTC, March 2) and monitoring guidance.
- [5] Reporting on App Store #1 ranking and “unprecedented surge in demand” statement.
- [6] Anthropic status incident updates (March 3, 2026) — elevated errors resolved by 10:18 UTC.